Napredek na področju različnih tehnologij je omogočil tudi zbiranje ogromne količine informacij. Trendi gredo v smer zajemanja, obdelave in interpretacije enormnih količin informacij, za kar je potrebno podatkovno rudarjenje. Na nivoju posameznega uporabnika se zbira veliko več informacij kot doslej – in še več se jih bo. Zaradi večjega števila podatkov bo toliko pomembneje izluščiti relevantne in jih pravilno interpretirati.
Eno od pomembnih (zapostavljenih) področij so A/B testi, ki omogočajo testiranje sprememb na spletnih straneh, pri čemer lahko še pred dokončno implementacijo ugotovimo, katere so obnesejo in katere ne. V pomoč so nam različna orodja, njihovo število, uporabnost in uporaba pa bodo letos v porastu.
In nenazadnje – že dolgo se ne moremo več pogovarjati o tipičnem prodajnem lijaku, ampak govorimo o atribucijskih modelih. Pri tem moramo zaradi kompleksnosti digitalnega marketinga upoštevati medsebojne vplive neštetih načinov in kanalov oglaševanja. Do sedaj smo za to potrebovali precej znanja in časa. Danes pa obstajajo orodja, ki nam lahko precej pomagajo pri iskanju optimalnih atribucijskih modelov.
V letošnjem letu lahko gotovo pričakujemo precejšnjo revolucijo v spletni analitiki.
1. Analitika, osredotočena na uporabnika
Večina podatkov, ki jih podjetja pridobivajo in analizirajo, je agregiranih. So seštevki ali povprečja za večji segment uporabnikov – žal še vedno najpogosteje kar za vse obiskovalce posameznih spletnih strani hkrati. Predvsem za potrebe oglaševanja in pospeševanja prodaje sicer pogosto analiziramo ožje segmente uporabnikov, a še vedno gre za več uporabnikov hkrati, ne pa za posameznika. V letošnjem letu lahko pričakujemo, da bodo podjetja, ki se zavedajo, kako pomembna je spletna analitika, začela pridobivati in analizirati podatke na nivoju posameznih uporabnikov. Tehnologija to že omogoča, od nas pa je odvisno, ali jo bomo izkoristili.
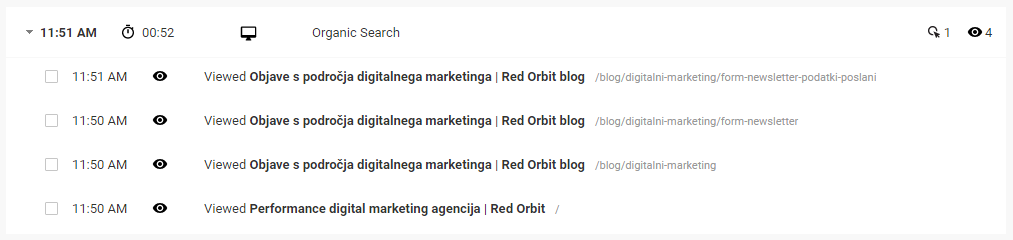
Poročilo iz orodja Google Analytics, ki prikazuje, kdaj je posamezen uporabnik obiskal našo spletno stran in kaj je med obiskom počel.
Podatke, ki jih dobimo na nivoju uporabnika, lahko izkoristimo na več načinov:
- za boljše profiliranje uporabnika,
- za izboljšanje uporabniške izkušnje,
- za izboljšanje konverzijske stopnje (pri prodaji in doseganju drugih ciljev na spletni strani …),
- za izboljšanje oz. optimizacijo oglaševalskih kampanj.
Vedno večje število podjetij, ki uporablja sistem CRM (ang. Customer relationship management), uporablja še eno rešitev: podatke s spletne strani lahko obogatimo s podatki iz sistema CRM. Na ta način imamo vse podatke o uporabniku zbrane na enem mestu. Najbolj pomembno pa je, da lahko na nivoju uporabnika med seboj povežemo njegove lastnosti iz sistema CRM in njegov vzorec obnašanja na naši spletni strani oz. na spletu. Tako lahko posameznega uporabnika še bolje profiliramo.
2. Premik od »nepomembnih« metrik in poročanja k analizi in razumevanju podatkov
Biti »data-driven« ne pomeni samo brati statistične podatke in poročila, kar je danes pogosta praksa. Biti »data driven« pomeni sprejemati poslovne in strateške odločitve na podlagi podatkov in pomembnih zaključkov, ki jih potegnemo iz njih. Metrika, kot je prihodek, ne pomeni nič, če se namesto kaj se dogaja oz. kakšen je prihodek ne vprašamo, zakaj je prihodek takšen, kot je. To nas prisili, da se zakopljemo v podatke in raziščemo, kako lahko prihodek povečamo. Rešitev je namreč skrita v podatkih, samo poiskati jo je treba. 🙂 Posledično se hitro začnemo ukvarjati z bolj kompleksnimi metrikami (npr. CLV, ang. Customer Lifetime Value), ki so pomembnejše od osnovnih.
[Tweet “Biti »data driven« pomeni sprejemati strateške odločitve na podlagi podatkov, ne le po občutku.”]
V letu 2017 lahko pričakujemo, da bo vedno več podjetij postalo »data-driven«. Na to kaže tudi globalen trend – povečanje potreb po kadrih, kot so npr. strokovnjaki za podatkovno rudarjenje.
3. A/B testi
A/B testiranje se danes preredko izvaja. Še sam ne vem, ali je težava v nepoznavanju koncepta ali v podcenjevanju te metode in rezultatov, ki jih lahko dobimo, ali gre enostavno za strah pred novim. Dejstvo pa je, da na svoji spletni strani rezultatov ne moremo izboljšati, če ničesar ne spremenimo. Poleg tega tudi konkurenca nikoli ne spi.
A/B testi nam omogočajo, da želene spremembe pred dokončno implementacijo testiramo in predvsem, da lahko vse pomembne podatke, ki jih dobimo v času testiranja, analiziramo. Na ta način ugotovimo, ali se bo sprememba obnesla. Najlepše pri tem pa je, da to naredimo na podlagi številk, ne na podlagi nekega občutka, ki je lahko varljiv.
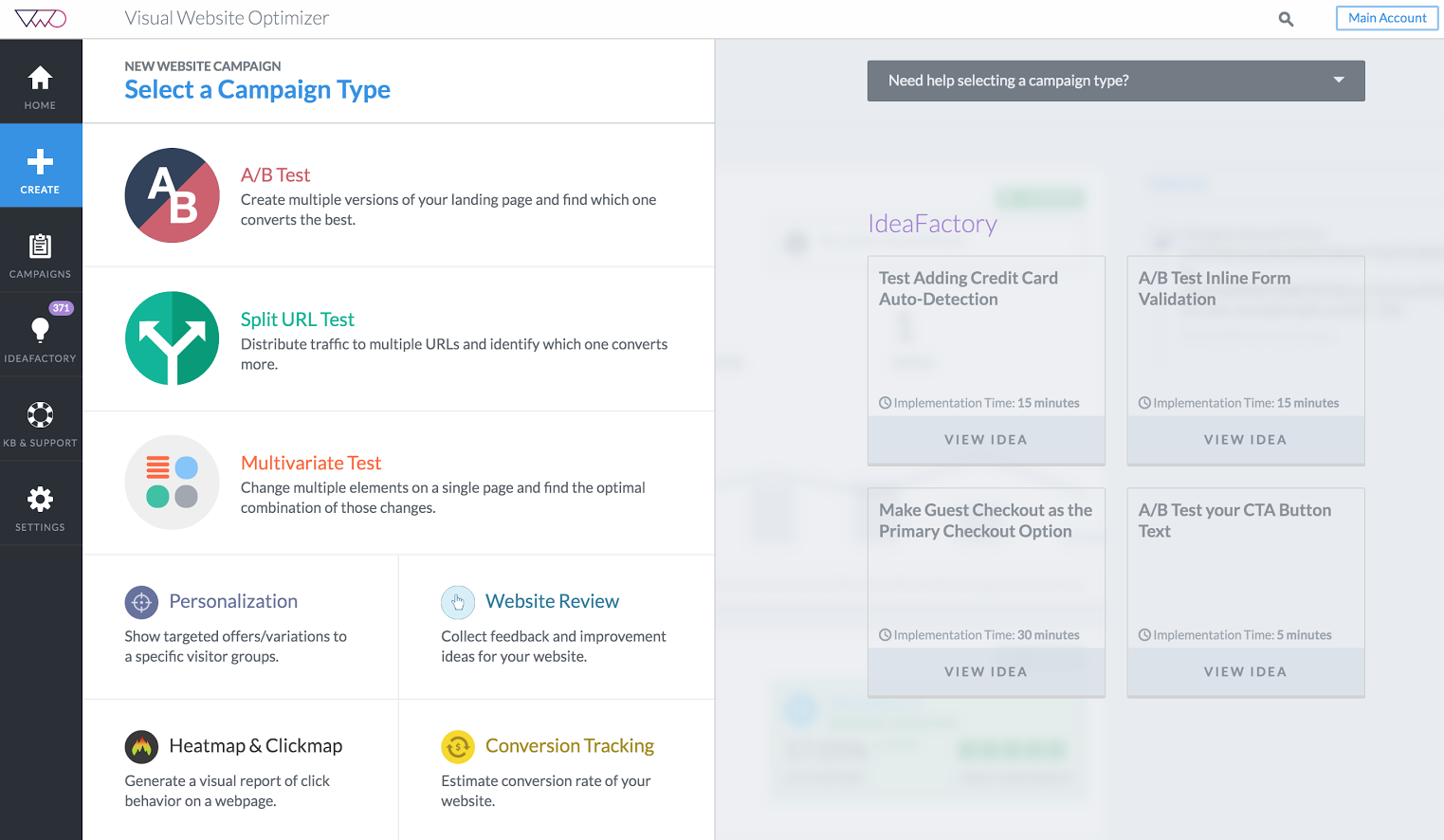
Priprava A/B testa z orodjem Visual Website Optimizer
4. Strojno učenje in avtomatsko podatkovno rudarjenje
Število kadrov, ki bi znali pravilno analizirati in interpretirati podatke ter na podlagi njih sprejemati pomembne odločitve, danes vsekakor raste precej počasneje kot količina informacij, ki je na voljo. Z napredkom tehnologije in predvsem porastom IoT (ang. Internet of Things) dobivamo množico naprav in storitev, ki so vseskozi online in vsebujejo morje informacij. Te informacije se shranjujejo v podatkovnih bazah, vendar je njihova količina tako velika, da z ročnim delom enostavno ne bo več mogoče priti do pametnih zaključkov oz. bo njihovo število izjemno majhno glede na potencial. Rešitev tega problema je avtomatsko podatkovno rudarjenje, pri čemer se seveda softver/hardver tudi sproti uči, kako naj to operacijo izvaja in kakšne informacije išče. Seveda lahko rečemo, da gre za vrsto umetne inteligence, a na srečo ne tako agresivno, kot jo poznamo iz filma I, Robot. 😉
V bolj tehnoloških panogah sta avtomatsko podatkovno rudarjenje in strojno učenje že pogosteje uporabljena, na področju spletne analitike pa zaenkrat bolj poredko. Zaradi vedno večje količine podatkov o spletnih uporabnikih in njihovem obnašanju, ki so na voljo, lahko v letošnjem letu tudi na področju spletne analitike pričakujemo povečano uporabo predvsem avtomatskega podatkovnega rudarjenja.
5. Atribucijski modeli
V offline svetu je zelo težko izmeriti, koliko uporabnikov je prišlo v fizično trgovino potem, ko so v poštni nabiralnik dobili katalog ali videli jumbo plakat in koliko potem, ko so dobili katalog in videli plakat oziroma obratno. V tem primeru smo uporabili 2 različni metodi, pri čemer ne vemo, kakšen vpliv imata ena na drugo in katera je uspešnejša v smislu kasnejše prodaje v trgovini.
Če potegnemo vzporednico z obiskom spletne strani, je tukaj podobno, a z eno pomembno razliko. Uporabnik našo stran vedno obišče prek določenega kanala, npr. iskalnika, oglasa, druge spletne strani, družabnih omrežij … Pomembna razlika med offline in online svetom – ki se zaradi tehnološkega razvoja sicer zmanjšuje – pa je, da lahko v online svetu natančno izvemo, kateri kanal najbolj deluje oz. prinese največ obiska in prodaje.
Atribucijski modeli nam pomagajo razumeti, kateri kanali najbolj vplivajo na doseganje ciljev, ki smo si jih s spletno stranjo zastavili (na tem mestu bomo poenostavili in rekli, da je glavni cilj prodaja) in kaj počnejo uporabniki na naši spletni strani, preden izvedejo nakup. Atribucijski modeli so pomembni, saj brez njih ne moremo pravilno utežiti posameznih kanalov. Zakaj je tako?
Ne bom šel v podrobnosti, saj ni namen članka podrobna razlaga atribucijskih modelov, zato naj poudarim samo osnove. Uporabniki na našo stran prihajajo prek različnih kanalov in to ne samo enkrat. Preden posamezen uporabnik izvede nakup, obišče našo stran večkrat in pogosto preko različnih kanalov.

Primer konverzijske poti v orodju Google Analytics
Na zgornji sliki vidimo podatke o eni izmed konverzijskih poti (na koncu se je namreč zgodil nakup). Iz njih je razvidno, da je uporabnik prvič na spletno stran prišel prek povezave na drugi spletni strani, naslednjič prek povezave v elektronski pošti, naslednjič prek organskega zadetka in na koncu prek plačljivega oglasa v iskalniku. Med zadnjim obiskom strani je izvedel nakup.
Od vrste atribucijskega modela je odvisno, kako utežimo posamezne kanale. Če celotno vrednost transakcije razdelimo na vse kanale (linearni model), potem so vsi kanali uteženi enako – v našem primeru imajo potem vsi štirje kanali utež 0,25. Če pa npr. vzamemo atribucijski model, ki upošteva samo zadnji obisk oz. zadnji kanal (ang. Last-click model), potem dobi kanal Paid Search utež 1, ostali trije pa utež 0. V tem primeru bi rekli, da ne bomo več pošiljali e-časopisa in skrbeli za optimizacijo spletne strani, saj prek teh dveh kanalov ne prodamo nič. Pa je res tako?
Ko zgornjo logiko ponovimo na vseh različnih konverzijskih poteh in pri tem upoštevamo še druge parametre, npr. znesek transakcije, lahko pridemo do lastnega atribucijskega modela, ki nam pove, kako uspešen je v resnici vsak kanal posebej in koliko doprinese k prodaji.
[Tweet “Skrajni čas je, da v digitalnem marketingu pričnemo z uporabo pravilnih atribucijskih modelov.”]
Last-click attribution model je daleč najbolj razširjen, a hkrati tudi napačen, saj ne upošteva vpliva ostalih kanalov. 2017 je leto, ko bo treba v digitalnem marketingu narediti miselni preskok in ta atribucijski model zamenjati z lastnim. Le na tak način bo naš digitalni marketing učinkovit.
V članku sem navedel trende in spremembe, ki jih lahko pričakujemo v letošnjem letu na področju spletne analitike. Se strinjate z njimi ali bi dodali še kakšno svojo?